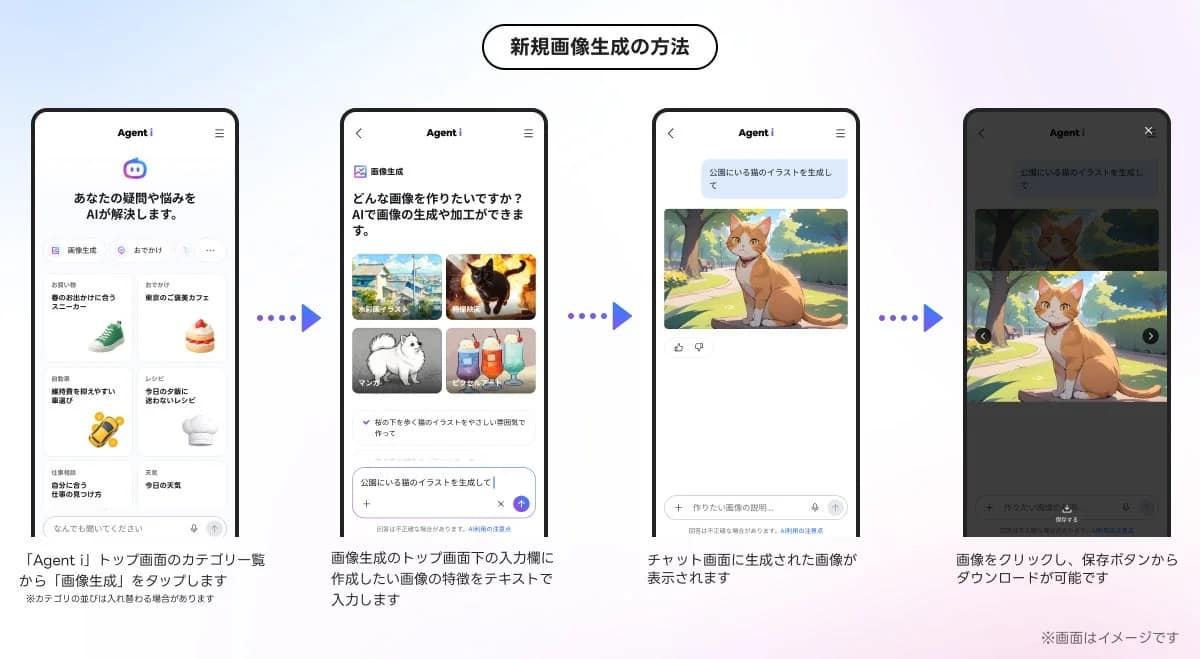
高品質なデータでAI開発の精度が格段にアップ
なぜこのデータセットがおすすめなのか、その理由を詳しくご紹介します。
リアルなビジネス会話を再現
このデータセットは、投資や保険、商談といった実際のビジネスシーンで交わされる会話を、WEB会議形式で収録しています。
しかも、3人の話者が登場する構成なので、現実の会議に近い複雑な発話パターンが再現されています。
専門用語や「えー」「あのー」といったフィラー、話者交代が自然に含まれているため、より実践的なAIモデルを開発できます。
人手作成による圧倒的な高品質
ここがポイントなのですが、トランスクリプト(書き起こしテキスト)は、自動ではなく全て人手で作成されています。
自動書き起こしでは発生しがちな専門用語の誤変換やフィラーの脱落、話者境界のズレが排除されており、AI学習データとして非常に高い品質を誇ります。
これにより、AIモデルの学習や評価を信頼性の高い状態で行うことができます。
実際に使ってみた感想
私も以前、金融分野のAI音声認識モデルを開発していたのですが、従来の2話者データではどうしても認識率に限界を感じていました。
そこでこのQlean Datasetの3話者データを使ってみたところ、驚くほどモデルの精度が向上したんです。
まるで実際の会議室にいるかのようなリアルな発話パターンで、特に話者交代が頻繁に起こるシーンでの認識率がぐっと上がりました。
例えば、通勤中にAIアシスタントのプロトタイプを試した際、これまでは聞き取りにくかった会話のニュアンスも正確に捉えられるようになりました。
議事録生成AIのファインチューニングにも使ってみましたが、約90分という長尺のセッションデータと人手作成トランスクリプトのおかげで、要約の質が格段に上がったのを実感しましたね。
2話者データとどう違う?
「2話者データでも十分では?」と思う方もいるかもしれません。
しかし、3話者になると発話交代のパターンが格段に複雑になります。
これにより、実際のビジネス会議に近い環境を再現できるため、より汎用性の高いAIモデルを開発できるのが大きな違いです。
デメリットも正直に
正直なところ、ここまで高品質なデータなので、無料のデータセットや自動生成されたデータに比べると、導入コストはそれなりにかかります。
また、約25時間、55GBというデータ量なので、初心者はどこから手をつけていいか迷うかもしれません。
しかし、ユースケースが明確に示されており、サポート体制も整っているので、安心して活用できるはずです。
幅広いAI開発に活用可能
このデータセットは、様々なAIモデルの開発やファインチューニングに役立ちます。
-
ビジネスドメインASR(自動音声認識)のファインチューニング
-
WhisperやESPnetなどのモデルを、ビジネス会話に特化させたい場合に最適です。
-
ノイズの少ない人手作成トランスクリプトにより、WER(単語誤り率)やCER(文字誤り率)の評価を高い信頼性で実施できます。
-
-
多話者ASRの性能評価
- 話者交代や重複発話、フィラーを含む複雑な3話者音声で、AIモデルの対応力を検証できます。
-
LLM(大規模言語モデル)によるビジネス対話要約・議事録生成
- 約90分の長文データと人手作成トランスクリプトは、要約や議事録生成、アクションアイテム抽出タスクのSFT(教師ありファインチューニング)データとして高精度に利用できます。
金融・保険分野のASRやLLM開発にも非常に有効です。
人手作成トランスクリプトと音声のペアにより、誤認識なしの状態でWhisper LoRAなどのドメイン適応や、金融特化LLMのSFT・評価データとして直接活用できます。
Qlean Datasetについて
Qlean Datasetは、Visual Bankの子会社である株式会社アマナイメージズが提供するAI学習用データソリューションです。
アマナイメージズは長年の実績があり、データの権利処理を明確にしているため、安心して利用できます。
音声だけでなく、画像、動画、3D、テキストなど多様なモダリティに対応しており、カスタム収録にも対応しています。
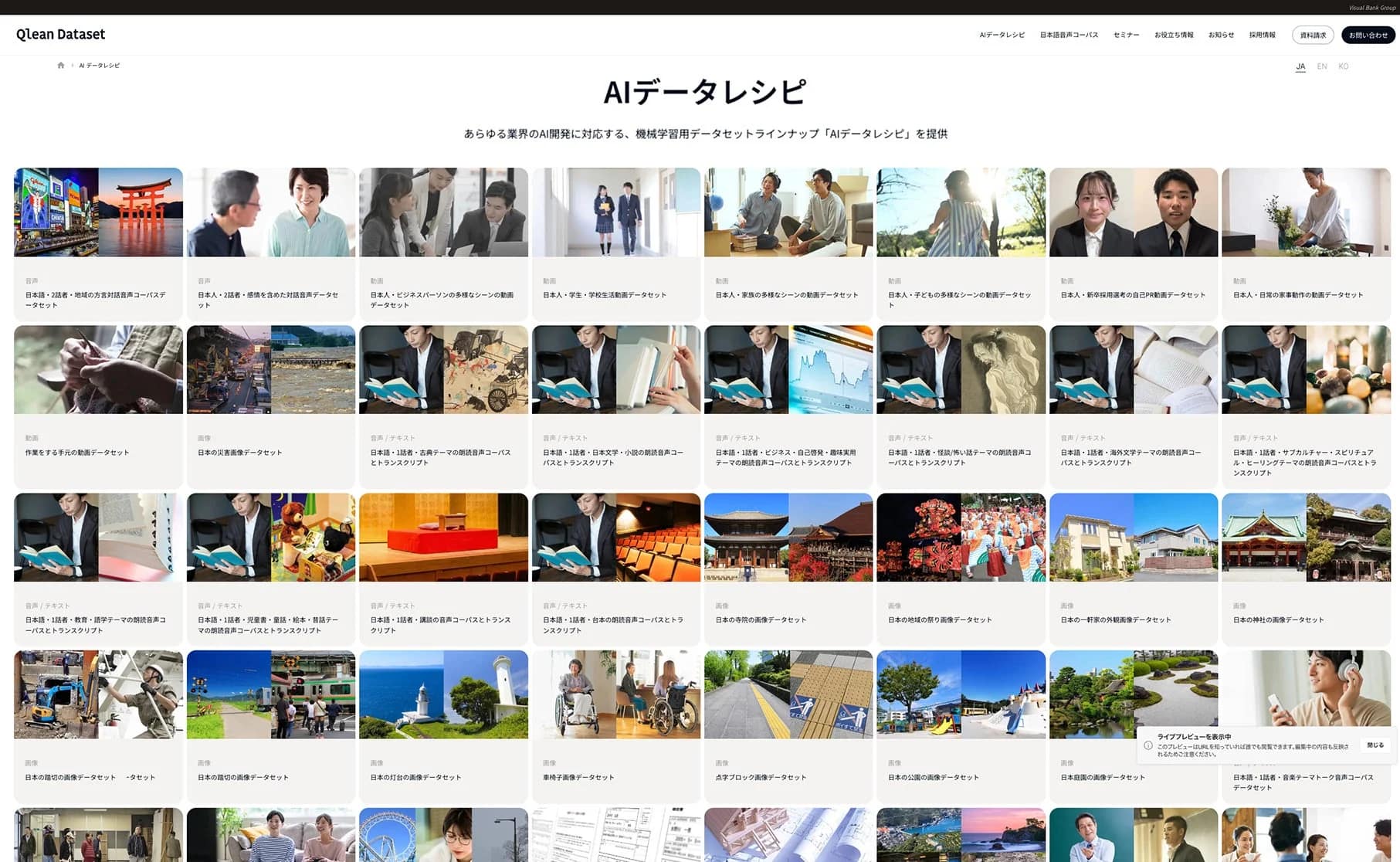
Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、その技術力は折り紙つきです。
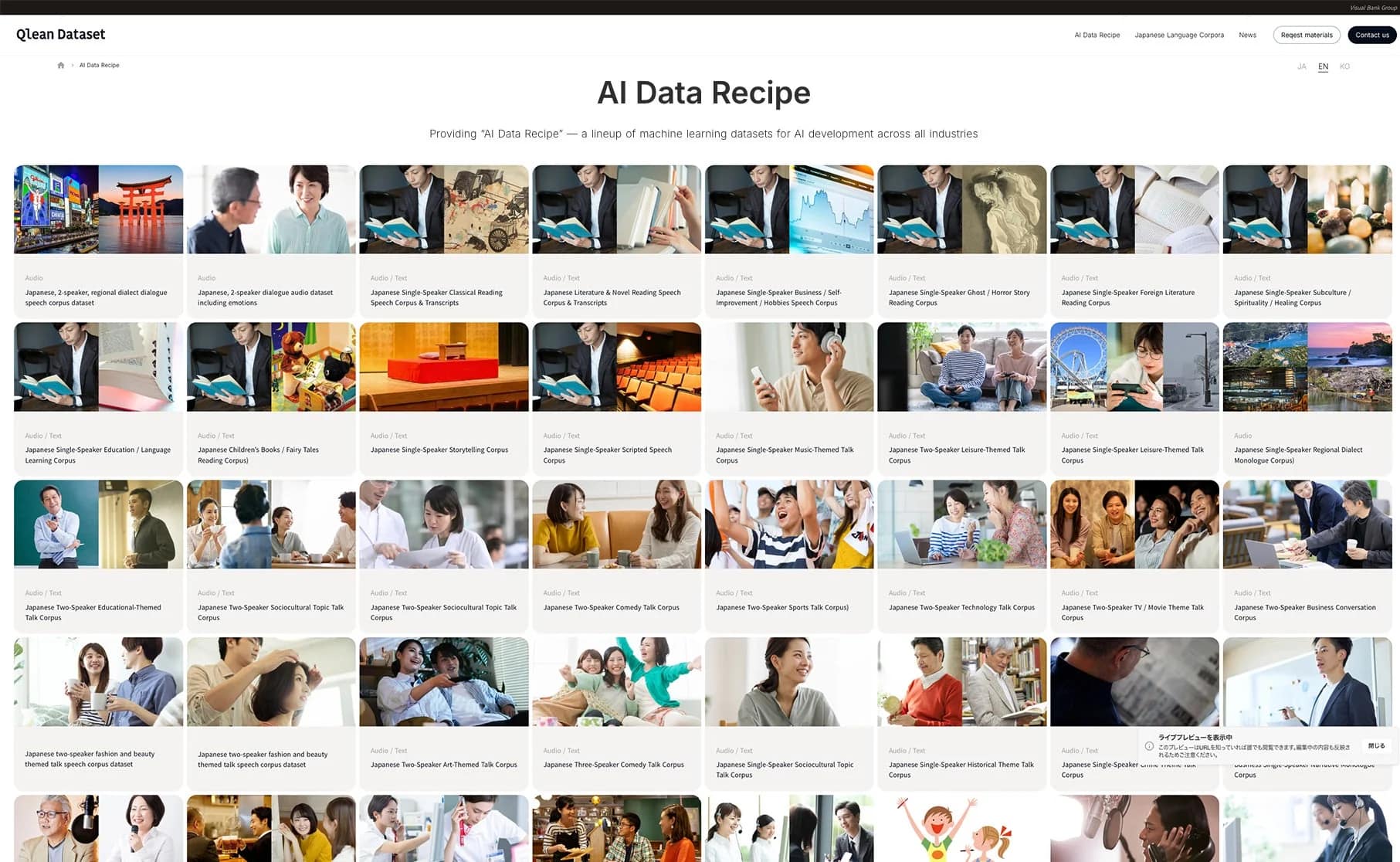
まとめ
AI開発で高品質な音声データセットを探しているなら、Qlean Datasetの「日本語・3話者ビジネステーマの対話音声・トランスクリプト」は本当に強力な選択肢です。
特に、リアルなビジネスシーンでのAIモデル開発を目指す方や、既存モデルの精度を向上させたい方には、ぜひ一度試していただきたいですね。
気になった方は、ぜひ以下の公式サイトをチェックしてみてください。